English-Spanish
Description
This tool draws on information stored in a database that is relevant to each text type under investigation. A relevant database necessarily contains textual, semantic and pragmatic information and can be worked upon independently of the software.
The software program facilitates the tagging process, providing easy access to the different blocks of text as necessary. The most salient features include:
- a high-level, user interface, permitting the use of different tag sets, for example, tags which identify blocks of text in a technical report, an audit or a financial document.
- tagged texts which, by means of a standard browser, are easily recoverable in one or both languages.
- design principles which permit as great a number of tag sets as any specific research study requires.
- innovative design which assures text searches are both precise and agile thereby ensuring savings in time and resources, both human and material.
- in addition to serving as a tool in various research processes, the ensuing results can be converted for use in applications that can aid the productive sector.
Tour
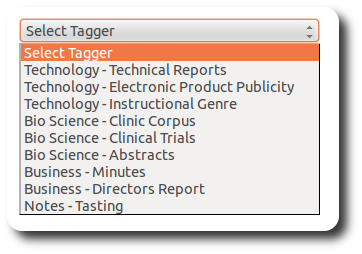 Highly versatile application. It is possible to work with up to nine different tag sets related to
several different research fields, for example, technology; biology and medical sciences; economics and
business; oenology.
Highly versatile application. It is possible to work with up to nine different tag sets related to
several different research fields, for example, technology; biology and medical sciences; economics and
business; oenology.
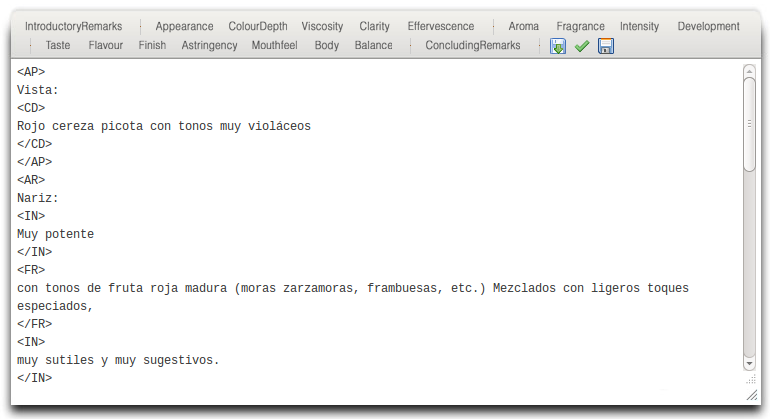 Clean user interface, designed to increase user productivity.
Clean user interface, designed to increase user productivity.
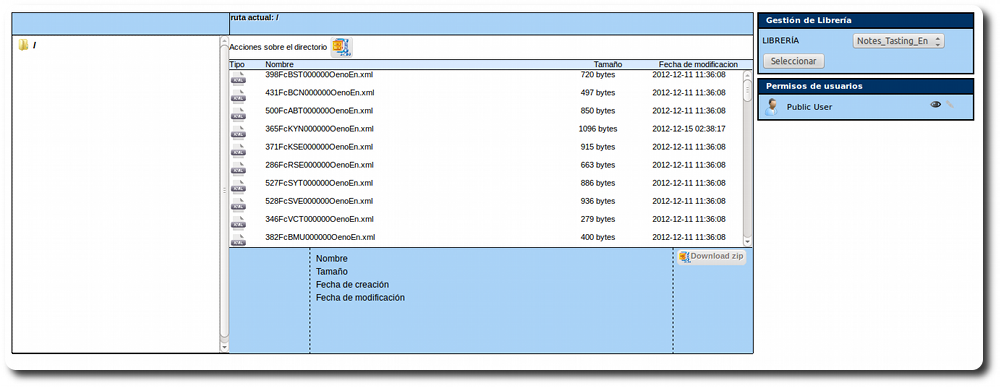 User-friendly management of corpora files.
User-friendly management of corpora files.